Instant industry overview Market sizing forecast key players trends. Instant industry overview Market sizing forecast key players trends.
 Building A Data Pipeline From Scratch By Alan Marazzi The Data Experience Medium
Building A Data Pipeline From Scratch By Alan Marazzi The Data Experience Medium
This helps you find golden insights to create a competitive advantage.

Big data pipeline. The misconception that Apache Spark is all youll need for your data pipeline is common. Big data pipeline can be applied in any business domains and it has a huge impact towards business optimization. This research should be of interest to big data.
For those who dont know it a data pipeline is a set of actions that extract data or directly analytics and visualization from various sources. Whatever the method a data pipeline must have the ability to scale based on the needs of the organization in order to be an effective big data pipeline. We also call this dataflow graphs.
Transcript of video subtitles provided for silent viewing Audrey. Ad Download Big Data Industry Reports on 180 countries with Report Linker. Enter the data pipeline software that eliminates many manual steps from the process and enables a smooth.
We might think of big data as a chaotic volume of data but actually most big data are structured. The volume of big data requires that data pipelines must be scalable as the volume can be variable over time. Designing a data pipeline can be a serious business building it for a Big Data based universe however can increase the complexity manifolds.
Dash Enterprise Enterprise IT Integration Big Data Pipelines Dash Enterprise is your front end for horizontally scalable big data computation in Python. Data Engineering Spark. Since Python connects to any database its easy to empower business users with Dash apps that connect to your databases query data perform advanced analytics in Python and even write back results.
How does a Business Get Benefit with Real-time Big Data Pipeline. The Five Types of Data Processing. The next ingredient is essential for the success of your data pipeline.
A data pipeline is a set of tools and activities for moving data from one system with its method of data storage and processing to another system in which it can be stored and managed differently. The tools and concepts around Big Data. Your pipelines architecture will vary in the method you choose to collect the data.
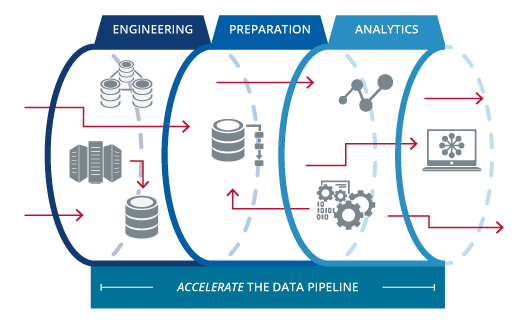
Ad Download Big Data Industry Reports on 180 countries with Report Linker. Theres a common misconception in Big Data that you only need 1 technology to do everything thats necessary for a data pipeline and thats incorrect. The following graphic describes the process of making a large mass of data usable.
Welcome everyone and thanks for joining todays webinar Monitor and Optimize Big Data Pipelines and Workflows End-to-end Todays Webinar will take about thirty minutes. As it can enable real-time data processing and detect real-time fraud it helps an organization from revenue loss. The reality is that youre going to need components from three different general types of technologies in order to create a data pipeline.
Monitoring and Alerting. Big Data Processing Pipelines. You need to gather metrics collect logs monitor your systems create alerts dashboards and much more.
Without scalability it could take the system days or weeks to complete its job. The Three Components of a Big Data Data Pipeline. The proposed big data pipeline employs an open and extendable system architecture that is capable of indiscriminately interacting with legacy and smart devices on automation networks as well as exposing a common data interface for industrial analytics applications to consume measured data.
A big data pipeline may process data in batches stream processing or other methods. If Big Data pipeline is appropriately deployed it can add several benefits to an organization. Data flows through these operations going through various transformations along the way.
The Data Pipeline. Either in batch or via streaming service. In practice there are likely to be many big data events that occur simultaneously or very close together so the big data pipeline must be able to scale to process significant volumes of data.
Moreover pipelines allow for automatically getting information from many disparate sources then transforming and consolidating it in one high-performing data storage. Unstructured data will require additional techniques to build a data pipeline upon it. In the big data world you need constant feedback about your processes and your data.
Monitor and Optimize Big Data Pipelines. Most big data applications are composed of a set of operations executed one after another as a pipeline. With an end-to-end Big Data pipeline built on a data lake organizations can rapidly sift through enormous amounts of information.
Automate your big data applications to manage your pipeline and improve agility and efficiency with Robins cloud-native big data-as-a-service. All approaches have their pros and cons.



